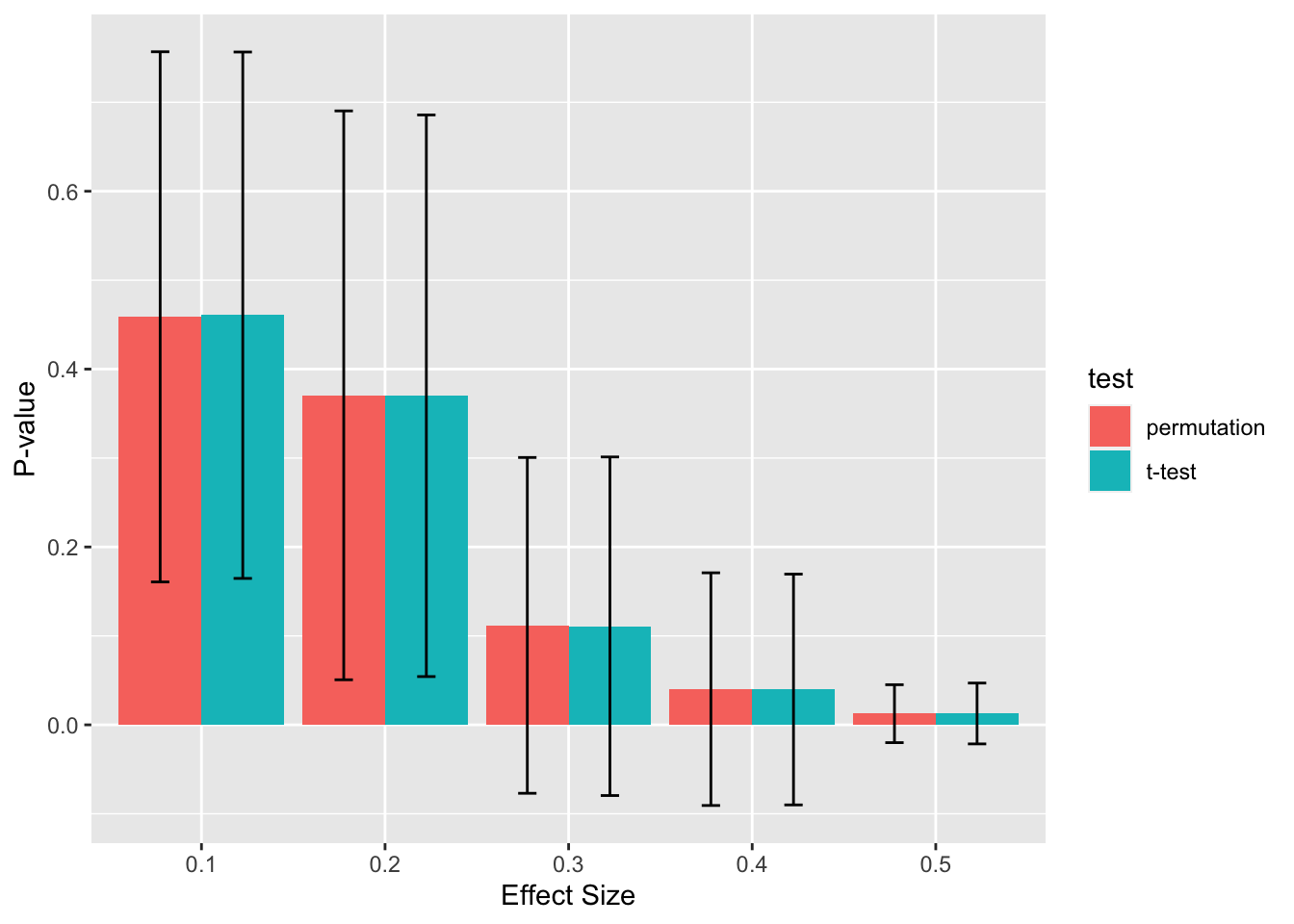
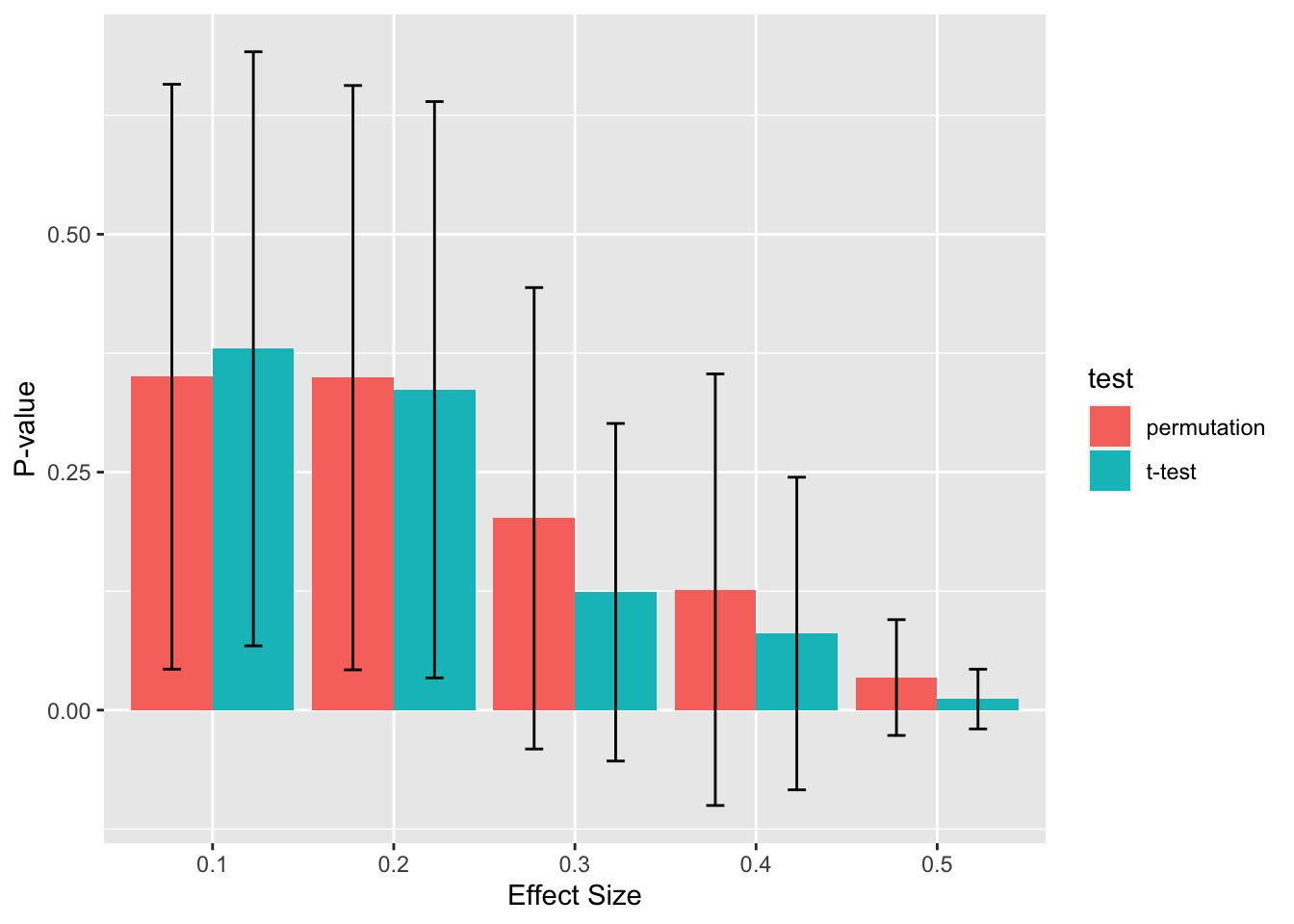
As you may have noticed above, sometimes the p-value was higher or lower for the permutation analysis than it was for the original analysis. Let’s use some simulations to capture what you can generally expect when using permutation analysis on data you can run a t-test on.
As most studies are on 30 participants or more, and we’ve established it is computationally unrealistic to compute all permutations of 30+ participants, we will use Monte Carlo simulations. We will conduct 50 simulations for Cohen’s d effect sizes of .1,.3,.5 of 1000 permutations for between-subject t-tests on 100 participants per group. All tests will be 2-tailed.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
simulations =50permutations_n =1000sample_size =100these_effect_sizes =c(.1,.2,.3,.4,.5)simulations_df <-data.frame(effect_size =rep(rep(these_effect_sizes, simulations)),simulation =rep(rep(c(1:simulations)),length(these_effect_sizes)),# permutation = rep(c(1:permutations_n), length(these_effect_sizes) * simulations),ttest =NA,perm_test =NA)# could take a while, here's a progess barpb =txtProgressBar(min =0, max =dim(simulations_df)[1], initial =0) for(i in1:dim(simulations_df)[1]){setTxtProgressBar(pb,i) this_effect_size = simulations_df$effect_size[i] group_1_data =rnorm(sample_size) group_2_data =rnorm(sample_size)+ this_effect_size simulations_df$ttest[i] =t.test(group_1_data, group_2_data, var.equal = T)$p.value# permutation analysis perm_vector =numeric(permutations_n)for(j in1:permutations_n){ all_sample =c(group_1_data,group_2_data) group_1_sample =sample(all_sample, sample_size, replace =FALSE)# select opposite data for group 2 group_2_index =!(all_sample %in% group_1_sample) group_2_sample = all_sample[group_2_index]# compare the medians perm_vector[j] =t.test(group_1_sample, group_2_sample, var.equal = T)$p.value } simulations_df$perm_test[i] =mean(abs(simulations_df$ttest[i]) >abs(perm_vector))}
As shown above, you get almost identical p-values from a single t-test on the original data to those from permutation analyses. However, arguably it’s redundant to do a permutation analysis of t-tests if the data is normal. The next question is whether a permutation analysis of median comparisons is equally powerful as t-tests on normal data? If so, then you could arguably just use permutation analyses of medians all times without having to worry about whether your data is parametric. Let’s see now how the p-values compare:
simulations_df <-data.frame(effect_size =rep(rep(these_effect_sizes, simulations)),simulation =rep(rep(c(1:simulations)),length(these_effect_sizes)),# permutation = rep(c(1:permutations_n), length(these_effect_sizes) * simulations),ttest =NA,perm_test =NA)# could take a while, here's a progess barpb =txtProgressBar(min =0, max =dim(simulations_df)[1], initial =0) for(i in1:dim(simulations_df)[1]){setTxtProgressBar(pb,i) this_effect_size = simulations_df$effect_size[i] group_1_data =rnorm(sample_size) group_2_data =rnorm(sample_size)+ this_effect_size simulations_df$ttest[i] =t.test(group_1_data, group_2_data, var.equal = T)$p.value# permutation analysis perm_vector =numeric(permutations_n) median_diff =median(group_1_data) -median(group_2_data)for(j in1:permutations_n){ all_sample =c(group_1_data,group_2_data) group_1_sample =sample(all_sample, sample_size, replace =FALSE)# select opposite data for group 2 group_2_index =!(all_sample %in% group_1_sample) group_2_sample = all_sample[group_2_index]# compare the medians perm_vector[j] =median(group_1_sample) -median(group_2_sample) } simulations_df$perm_test[i] =mean(abs(perm_vector) >abs(median_diff))}